Dedicated to curating and developing innovative methods of computational text analysis for the research community at UC Berkeley.
Find Out MoreDuring the Spring of 2015 a group of UC Berkeley researchers including faculty, graduate students, and other affiliated researchers realized that there was no centralized community to support the innovative methodological experimentation with rapidly evolving field of computational text analysis. To support these efforts, and to develop a broad community capable of leveraging these new tools to contribute to research in a wide range of fields, we launched the CTAWG. We meet twice a month to share research, provide technical workshops, and to offer space to support ongoing analysis. We welcome new members and we have lots of ways for you to get involved so please be in touch if you'd like more information.
Get Involved!We meet every other week on Fridays from 1:00-2:00 PM PST over Zoom. Meetings are open to the Berkeley and UCSF communities - please make sure to register. We're planning to have nine meetings for Spring 2021: 1/29, 2/5, 2/19, 3/5, 3/19, 4/2, 4/16, 4/30, 5/7.
We host a lively ongoing discussion on our listserve featuring event listings, workshops, and news for the computational text analysis community at UC Berkeley. To join our listserv fill out a registration form at D-Lab.
We’re compiling a list of critical citations, both technical and applied, that can guide future computational text analysis. To see what we have, or to add your own resources, visit the CTAWG at Zotero, log in, and request an inviation to join.
We do our best to keep records of our meetings, plans, and accomplishmnets. If you missed something and you'd like to get caught up, or if you'd like to contribute notes or suggestions, check out or documentation page.

Computational text analysis methods are flexible enough to provide valuable tools for researchers with a clear question who are interested in testing a hypothesis, or to provide fruitful preliminary insight into a broader research topic.

The internet has created unparalleled access to huge volumes of digital text (e.g. Project Gutenberg, Wikipedia, LexisNexis, Twitter, the web itself). While designing an analysis around such data can save time, these methods can be used on virtually anything in the form of text.
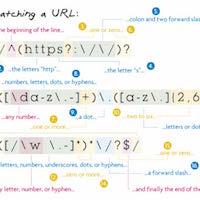
The plethora of digital text that now exists is rarely available in interoperable or standardized formats. Analyzing this data often calls for what can be tedious and time consuming efforts to ensure that your analysis captures only the data of interest.
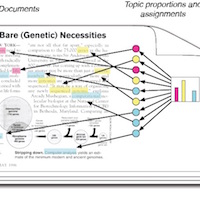
A wide array of methods exist which leverage modern computing power to analyze text. Among the many methods available are those which can be used to count words, discover latent topics in text, or to classify new documents bases on rules.

Due to the novelty, sophistication, and complexity of many text analysis methods, interpretation of output and reporting of results require extra care. Documenting and justifying choices at this stage is critical.

Presenting or publishing results of computational text analysis often benefit from visual summaries. In addition to traditional quantitative statistical software (e.g. R, Stata, Excel, Python) a few specific options are available for text analysis (e.g. Mallet).
If you have additional questions, or if you'd like to speak with a group organizer, don't hesitate to contact us via our email. You can also use the D-Lab's contact form for help with individual research projects or you can choose the CTAWG organizers from the D-Lab CTAWG page for their contact information.


